Anthropic shipped Claude Fable 5 on June 9, 2026, and the headline is simple: this is the first generally available Mythos-class Claude model, priced at $10 per million input tokens and $50 per million output tokens, with a 1M-token context window and 128k max output (Anthropic launch, model docs, pricing docs). If you are evaluating it today, do not start with a benchmark tweet. Start with one hard workflow from your own backlog, wire it up, cap spend, and measure whether fewer turns offsets the higher meter.

What Claude Fable 5 Actually Is
Claude Fable 5 is Anthropic’s public version of a Mythos-class model. Anthropic describes Mythos-class as a tier above Opus, with Fable 5 made safe for general use and Mythos 5 reserved for limited trusted access through Project Glasswing (Anthropic). In practical developer terms, Fable 5 is the “use this when Opus is not enough” model.
The API model ID is:
claude-fable-5Anthropic’s model overview lists these current specs (Anthropic docs):
| Model | API ID | Context window | Max output | Input | Output |
|---|---|---|---|---|---|
| Claude Fable 5 | claude-fable-5 | 1M tokens | 128k tokens | $10 / MTok | $50 / MTok |
| Claude Opus 4.8 | claude-opus-4-8 | 1M tokens | 128k tokens | $5 / MTok | $25 / MTok |
| Claude Sonnet 4.6 | claude-sonnet-4-6 | 1M tokens | 64k tokens | $3 / MTok | $15 / MTok |
| Claude Haiku 4.5 | claude-haiku-4-5-20251001 | 200k tokens | 64k tokens | $1 / MTok | $5 / MTok |
That table tells you where Fable fits. It is not the cheap default. It is the model to try when the task is long, messy, and expensive to get wrong: multi-repo migrations, agentic coding, legal or finance document reasoning, long planning jobs, and workflows where prior models burned time through correction loops.
There is one important safety behavior: Anthropic says Fable 5 uses classifiers for areas including cybersecurity, biology and chemistry, and distillation. Flagged requests fall back to Claude Opus 4.8, and users are informed when this happens (Anthropic). Anthropic also says more than 95% of early Fable sessions had no fallback. If your product lives near those domains, test the fallback path explicitly.
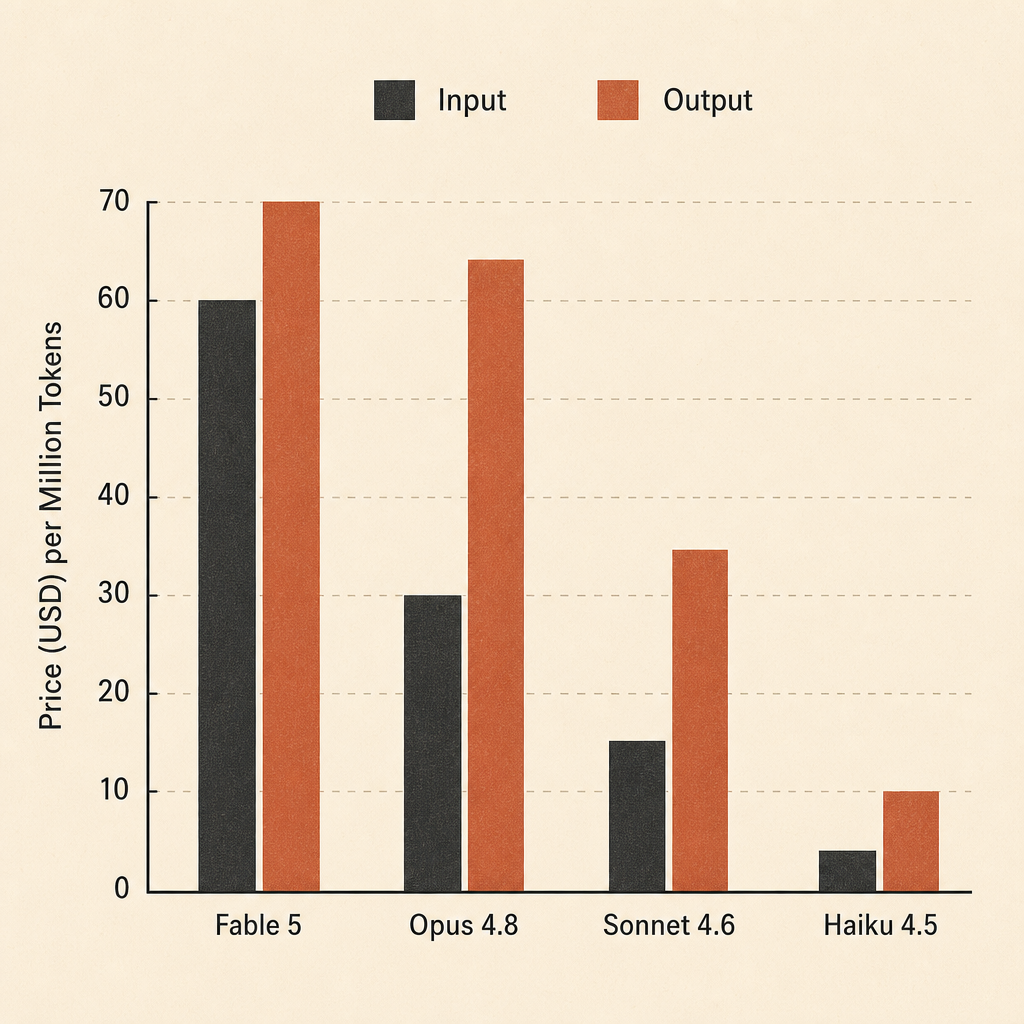
Pricing: The Real Meter
The list price is clear: $10 / MTok input, $50 / MTok output. Prompt caching follows Anthropic’s standard multiplier structure: 5-minute cache writes at 1.25x input, 1-hour cache writes at 2x input, and cache reads at 0.1x input (Anthropic pricing). For Fable 5, that means:
| Billing item | Fable 5 price |
|---|---|
| Input | $10 / MTok |
| Output | $50 / MTok |
| 5-minute cache write | $12.50 / MTok |
| 1-hour cache write | $20 / MTok |
| Cache read / refresh | $1 / MTok |
Anthropic’s Fable product page also states US-only inference is available at 1.1x pricing for input and output tokens (Anthropic Fable page). That matters if you are building for customers with data residency requirements.
For OneHop, the model page currently lists anthropic/claude-fable-5, a 1000K context label, Anthropic Messages availability, and a new-account $10 free credit offer with no card required (OneHop). OneHop’s page also shows discounted pricing versus the official rate. If you want the fastest evaluation path without setting up direct Anthropic billing, start at Claude Fable 5 on OneHop or start with $10 free.
Benchmarks Without the Fog
Anthropic says Fable 5 is “state-of-the-art on nearly all tested benchmarks” and strongest on longer, more complex tasks (Anthropic). The benchmark table in Anthropic’s launch post is published as an image, so treat copied numbers elsewhere as vendor-reported unless the evaluator hosts the run.
The numbers developers keep comparing are coding-heavy:
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | Source context |
|---|---|---|---|
| SWE-Bench Pro | 80.3% | 69.2% | Reported by third-party summaries of Anthropic’s launch table (TrueFoundry) |
| SWE-bench Verified | 95.0% | 88.6% | Reported from Anthropic/system-card summaries (LMM Marketcap) |
| FrontierCode Diamond | 29.3% | 13.4% | Reported from Anthropic/system-card summaries (LMM Marketcap) |
Use these as a reason to test, not as a procurement decision. Fable 5’s pitch is long-horizon autonomy. A 10-minute chat prompt will not tell you much. A real migration branch, a production incident runbook, or a messy “read these 40 files and propose the smallest safe patch” task will.
Call It Directly with the Anthropic SDK
Anthropic’s official SDKs support Python, TypeScript, Go, Java, C#, PHP, and Ruby, with streaming, retries, and typed interfaces depending on language (Anthropic SDK docs). Here is the smallest useful Python call.
Install:
python -m venv .venv
source .venv/bin/activate
pip install anthropic
export ANTHROPIC_API_KEY="sk-ant-..."Create fable.py:
from anthropic import Anthropic
client = Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
message = client.messages.create(
model="claude-fable-5",
max_tokens=800,
messages=[
{
"role": "user",
"content": "Review this migration plan for risk. Return the top 5 issues and concrete fixes.",
}
],
)
print(message.content[0].text)Run:
python fable.pyOne fix: add the missing import if you copy this into a file:
import osFor Node.js:
npm install @anthropic-ai/sdk
export ANTHROPIC_API_KEY="sk-ant-..."import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
});
const message = await client.messages.create({
model: "claude-fable-5",
max_tokens: 800,
messages: [
{
role: "user",
content: "Turn this product brief into an implementation plan with risks and test cases.",
},
],
});
console.log(message.content[0].type === "text" ? message.content[0].text : message.content);For first tests, keep max_tokens low. Output is the expensive side of this model.
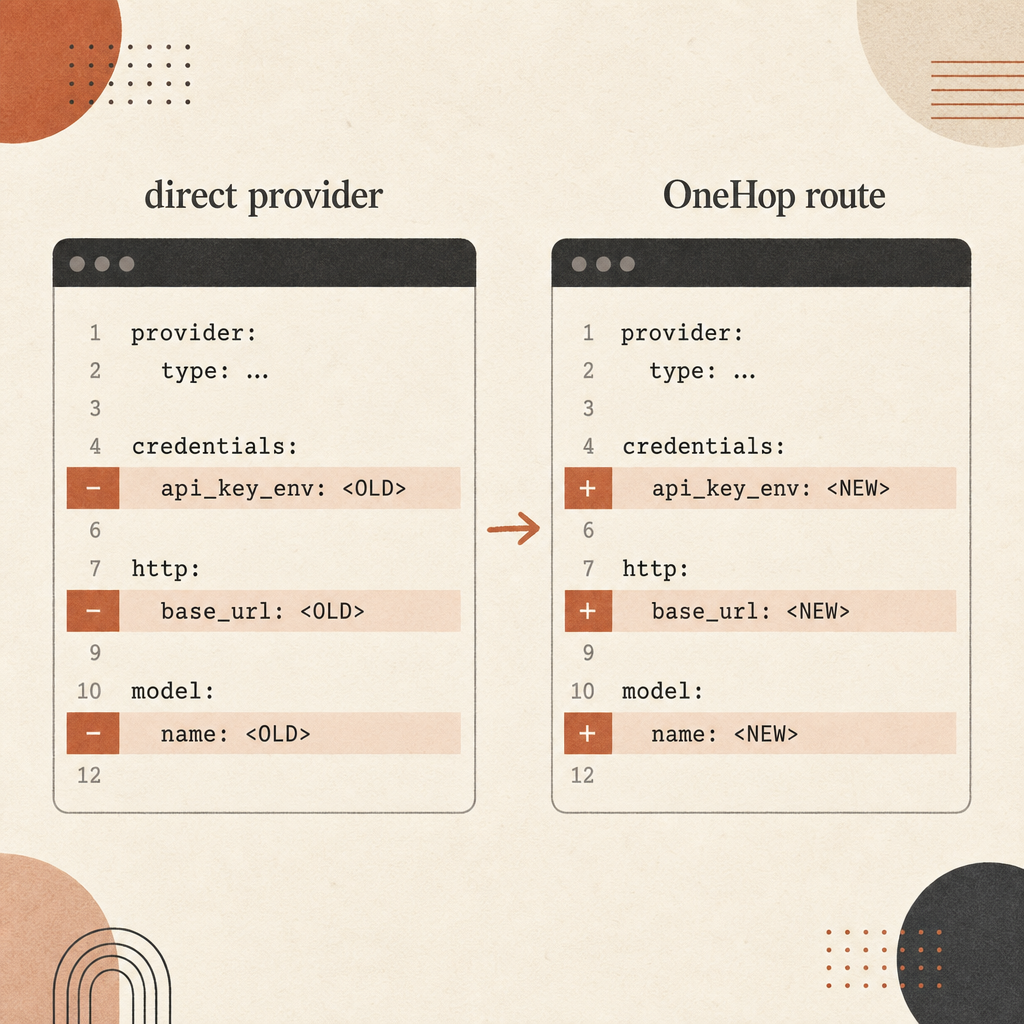
Call It Through OneHop with a Base URL Change
If you want to evaluate Fable 5 quickly, OneHop is the low-friction path: create an account, get the free starting credit, and point your client at OneHop instead of wiring direct provider billing. The current OneHop model page shows Anthropic Messages support and a Python example using the Anthropic SDK with base_url="https://api.onehop.ai/anthropic" (OneHop).
Install the same SDK:
pip install anthropic
export ONEHOP_API_KEY="oh_..."Use the OneHop route:
import os
from anthropic import Anthropic
client = Anthropic(
base_url="https://api.onehop.ai/anthropic",
api_key=os.environ["ONEHOP_API_KEY"],
)
message = client.messages.create(
model="anthropic/claude-fable-5",
max_tokens=800,
messages=[
{
"role": "user",
"content": "Analyze this failing CI log and suggest the smallest likely fix.",
}
],
)
print(message.content[0].text)That is the practical drop-in change: same Anthropic SDK shape, different base_url, different API key, and OneHop’s model name.
If your integration standardizes on an OpenAI-style gateway, OneHop’s conversion path is the same idea: set your gateway base URL to https://api.onehop.ai/v1, pass your OneHop key, and route the request to Claude Fable 5 through OneHop’s model ID. In production, keep the provider route behind config:
LLM_BASE_URL="https://api.onehop.ai/v1"
LLM_MODEL="anthropic/claude-fable-5"Do not hard-code this in application logic. Make it an environment variable so you can compare Fable 5, Opus 4.8, and cheaper models under the same harness.
A Sensible Evaluation Plan
Here is the plan I would use before moving real traffic:
- Pick three tasks that currently fail or need too many correction turns.
- Run them on your current model and on Fable 5 with identical prompts.
- Log input tokens, output tokens, wall time, retries, and human edits.
- Check whether any request falls back to Opus 4.8.
- Route only the top-value class of work to Fable 5.
The model is expensive enough that “make it the default” is probably wrong for most teams. A better architecture is a router: Haiku or Sonnet for cheap extraction, Opus for strong general work, Fable for the handful of jobs where autonomy and context depth matter.
Prompt caching is also mandatory for serious use. If your request includes the same repo summary, policy bundle, schema, or long instruction block across calls, cache it. On Fable 5, a cache read is $1 / MTok instead of $10 / MTok, which changes the economics fast.
Ship the Spike, Then Decide
Claude Fable 5 is worth testing if your bottleneck is not “we need cheaper completions” but “we need the model to stay coherent across a large, multi-step job.” The current facts are strong enough to justify a spike: June 9 launch, 1M context, 128k max output, $10 / $50 list pricing, prompt-cache discounts, and a safety fallback you need to understand before production.
For the fastest path, use the Anthropic SDK directly or point the same style of call at OneHop. If you want to avoid billing setup and just run a practical evaluation, open Claude Fable 5 on OneHop, grab the model ID, and start with $10 free. Then run your hardest real task. That is the only benchmark that will survive contact with your codebase.

